One of the core Cybereason products is designed to run on the user’s machine and block advanced MalOps (malicious operations) in real-time. This requires a heuristic model, embedded in a C++ application, that runs on millions of machines simultaneously. To complicate things even further, the app runs on machines we don’t own and have limited access to.
Throughout the last four years, we’ve developed an award-winning malware prevention stack that uses a machine learning model for the decision phase, and have faced several challenges worth sharing.
In this article you’ll get an overview of the project’s key challenges, which are quite common on “distributed” ML architectures frequently seen in IOT products, mobile and cybersecurity. In addition, I’ll describe the solutions that led this product to become best in its class (objectively).
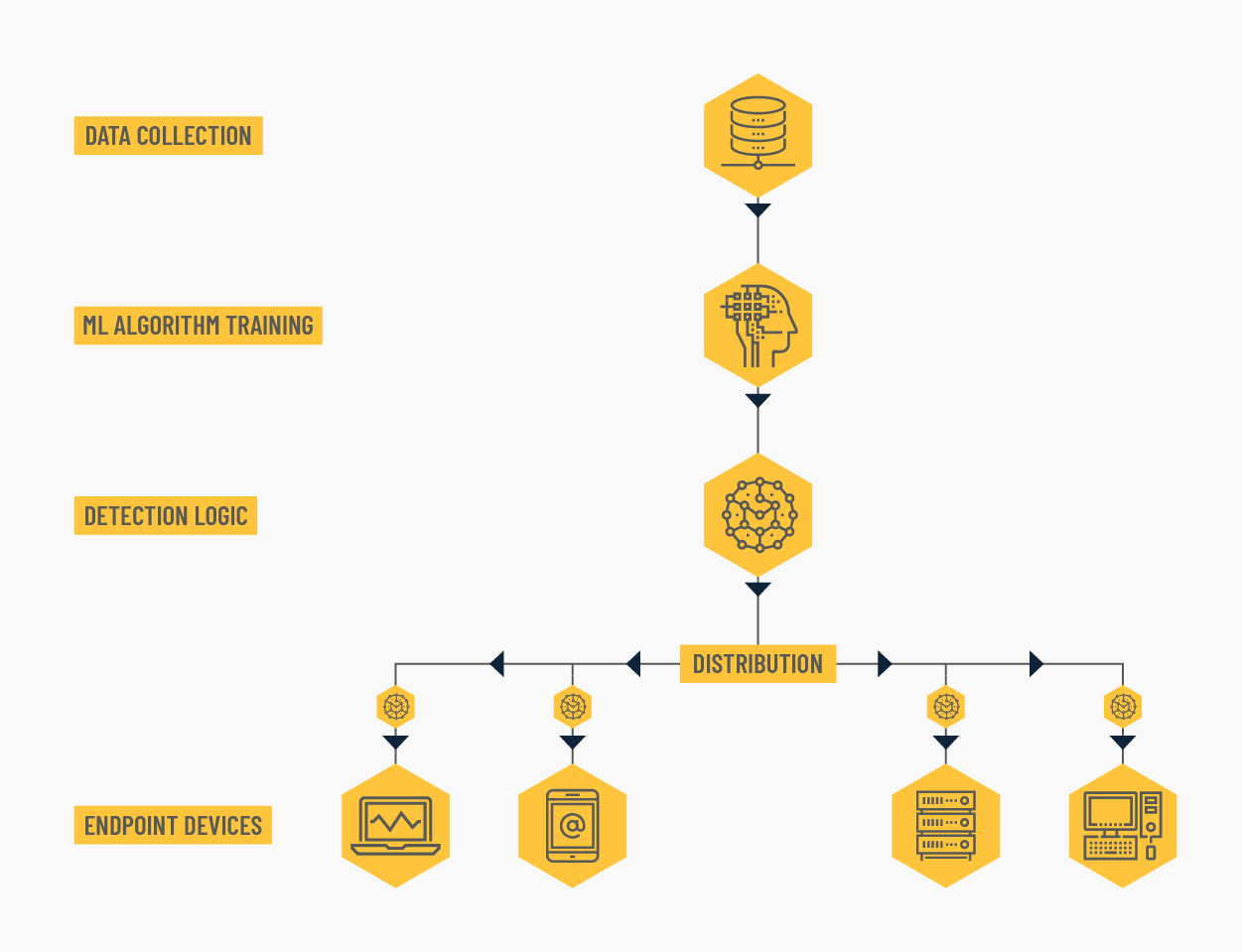 Distributed ML model architecture
Distributed ML model architecture
Challenge 1 - Data Distribution in Production
The deployment of a new model to production always comes with some uncertainties, particularly with the first version out there. Now, imagine you need to deploy the model to production when:
- Every false positive would literally block a legitimate application; and every false negative might lead to a security breach; meaning that any mistake could lead to catastrophic outcomes
- You can’t publish a new model version any time you want
- There’s no staging environment
This combination might lead to some sleepless nights for you and everyone involved. However, cyber-villains wait for no one and we must protect our users. So let’s see how you can mitigate such real-life scenarios:
Simulate a Production Environment
Using an external source of samples is clearly suboptimal but could lead to large training sets, which are key for a well performing model. The trick here would be to collect just enough “real-world” samples to simulate distributions, and class distributions in particular, so that threshold calibration and performance validation are viable.
We used a feed source, of which samples are quite random, but whose trends are well correlated with production trends. This proved to be good enough for the first version of the production model.
Use a Beta-Site to Test the Application End-to-End
This method can uncover critical issues before launching the product to users. We were brave enough to run our application on our own machines, to experience the behaviour first hand.
Build a Fail-Safe Mechanism
Design fast and effective remediation tools that could help tackle potential problems in the field. These are priceless when the worst case scenario occurs, and believe me it’s often even worse than you expected...
Here are some “fail-safe” mechanisms we used for our product:
- Enable user-defined allow-list mechanisms
- Design a “detection sensitivity” policy concept, allowing the user and our support team to modify how aggressive the logic is and even to turn this feature off if needed
Challenge 2 - Performance Monitoring
Having multiple instances of your model run on machines, which we don’t have direct access to to introduce significant monitoring challenges. Here are two key obstacles we came across, and our way to cope:
Telemetry Collection
Having the model run in the context of a customer owned machine makes telemetry fetching not trivial at all. Without this data collection, there’s no reliable way to know how your model performs “in the field”.
To overcome this, we designed a data pipeline that collects events from the endpoints, transforms the data and makes it available for research and operational purposes.
Data records are anonymous for privacy and GDPR (General Data Protection Regulation) considerations, and contain both the prediction and feature vector of every sample. This way, we can monitor our KPIs and look into features’ distribution drifts and anomalies, and so better optimize the model with every version.
Data Aggregations
Millions of model instances produce a massive amount of events every day; many of which are duplicated predictions for the same sample. As a private company, winning the market takes more than winning product awards - we need to be as profitable as possible. Since cloud costs are a significant factor, data needs to be managed wisely.
Here, our approach to loss-less compression was to aggregate events by sample ID in the context of every organization, while keeping count statistics. Calculating metrics “weighted” by sample ID prevalence yields the same results for far lower cloud costs:
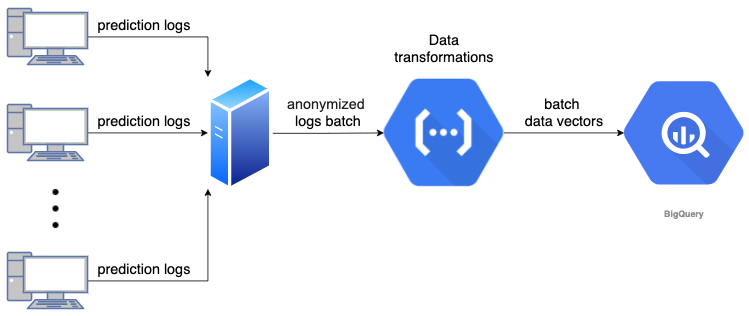 Telemetry Collection Concept
Telemetry Collection Concept
Challenge 3 - Model Updates Friction
I’ve mentioned that deployment on a customer machine means a non-trivial delivery of model versions. So this is one aspect to address, but another significant issue lies in the transition phase.
Imagine you’re a security officer that uses an ML based prevention solution, feeling good about the static analysis coverage capabilities and being willing to pay with the occasional false positive that needs to be cleaned manually.
Eventually, your environment runs quite smoothly and you have quiet time for coffee and cookies. Now, there’s a version update and suddenly you’re flooded with new detections that need to be addressed quickly - a very annoying yet realistic scenario.
Now let me explain why that is - every new model version is well tested and statistically superior to its predecessor, leading to improved security coverage. However, this new “hypothesis” does have its own unique mistakes, which translate to new false positives. Creating a frequent surge in false positives would lead to frustrated users, and that’s unacceptable.
We came up with two approaches to address this issue:
- Have a “silent model” run side-by-side with the “active model”, and report back events for evaluation. This way, we can test prediction and clean model mistakes using an offline, automated framework.
- Create an “allow-list” for all production samples during the model generation pipeline, and have it bundled to the model release. For this task, we used the collected telemetry described in the second challenge, which contains anonymized feature vectors of all production samples.
Eventually, we decided to proceed with the second alternative, as it avoids customer-side risks and resource utilization. However, keep in mind that this approach would not work well in cases where your new model uses a different set of features. If you expect such dynamics between versions, the first alternative would be a better fit.
Wrapping Up
Embedded models pack a unique set of challenges, stretching from dataset distributions to deployment management. We’ve discussed some key aspects that were prominent on our use case, which required hardcore machine learning operations engineering (A.K.A MLOps) combined with data science.
As MLOps discipline matures, I hope we’ll get to see off-the-shelf solutions for remote ML models’ serving. Until then - harness your organization resources for creative solutions and try to rely as much as possible on best practices. Upwards and Onwards!



